Bitcoin is a digital currency. Like other currencies, you can use it to buy things from merchants that accept it, such as Overstock.com, or, as is more often the case, hold on to it in hopes that it will increase in value. Unlike traditional currencies, which rely on governments and central banks, no single entity controls bitcoin. Rather, it is supervised by a worldwide network of volunteers who maintain computers running specialized software. As long as people run bitcoin software, the currency will keep working, because everything needed to keep it working is stored in a distributed ledger called the blockchain. And even though it’s all digital, bitcoin is scarce.
Its most wild-eyed proponents believe bitcoin’s decentralized, cryptographic approach to currency can yield a host of benefits: limiting central bankers’ ability to damage economies by printing too much money; eliminating credit-card fraud; bringing the unbanked masses into the modern economy; giving people in unstable economies a safe place to park their money; and making it cheap and easy to transfer funds. But bitcoin has yet to realize these goals, and critics argue it may never live up to the hype.
When you send or receive bitcoin, your bitcoin software, referred to as a “wallet,†records the transaction in the blockchain. The blockchain is maintained by, and distributed across, the roughly 200,000 computers running bitcoin software. If someone tries to alter the ledger to make it look like they have more bitcoin than they’re supposed to, the tampering will be apparent because it won’t match the other copies of the blockchain.
People who commit the computing resources to processing bitcoin transactions are paid in bitcoin, but only if the computers they operate are first to complete complex cryptographic puzzles in a process called “mining.†New bitcoins are created automatically by the software and awarded to the winners of the race to solve these puzzles. As of February 2018, that award is 12.5 bitcoins. By design, only 21 million bitcoins will ever be created. Those who process transactions can also collect fees; the fees are optional and set by the person who initiates a transaction. The larger the fee, the faster the transaction will likely be completed. This system keeps bitcoin scarce while rewarding people for investing in the infrastructure required to keep a global payment-processing system running. But the mining process comes with a big catch: It uses an enormous amount of electricity.
Adoption of the cryptocurrency has been hobbled by a series of scandals, high-tech heists, and disputes over the software’s design, all of which illustrate why financial regulations were created in the first place. The bitcoin community has solved some mind-boggling technological problems. But making bitcoin a true replacement for, or even adjunct to, the global financial system requires more than just great tech.
The History of Bitcoin
On Halloween 2008, someone using the name Satoshi Nakamoto sent an email to a crytography mailing list with a link to an academic paper about peer-to-peer currency. It didn’t make much of a splash. Nakamoto was unknown in cryptography circles, and other cryptographers had proposed similar schemes before. Two months later, however, Nakamoto announced the first release of bitcoin software, proving it was more than just an idea. Anyone could download the software and start using it. And people did.
In the early days, bitcoin was used almost exclusively by cryptography geeks. A bitcoin sold for less than a penny. But the idea slowly caught on. Bitcoin emerged in the aftermath of the 2008 financial crisis when some people—especially free-market libertarians—worried the Federal Reserve’s attempts to increase the money supply would lead to runaway inflation.
Nakamoto disappeared from the internet before bitcoin attracted much mainstream attention. He handed control of the project to an early contributor named Gavin Andresen in December 2010 and quit posting to the public bitcoin forum. To this day, Nakamoto’s identity remains a mystery.
No one knows who the creator of bitcoin really is. These are a few of the suspects.
The value of a bitcoin first hit $1 shortly after this transition, in February 2011. Then the price jumped to $29.60 in June 2011 after a Gawker story about the now-defunct black-market site Silk Road, where users could use bitcoin to pay for illegal drugs. But the price fell again after Mt. Gox, the most popular site at the time for buying bitcoin with traditional currency and storing them online, was hacked and temporarily went offline.
The price fluctuated over the next few years, soaring after a financial crisis in Cyprus in 2013, and sinking after Mt. Gox went bankrupt in 2014. But the overall trajectory was up. By January 2017, bitcoin was trading at nearly $1,000. The price soared in 2017, reaching an all-time high of nearly $20,000 in December. The reasons for this rally are unclear, but it seems to have been driven by a mixture of wild speculation and regulatory changes (the US approved trading bitcoin futures on major exchanges in December).
Bitcoin’s price surged despite discord among its adherents over the currency’s future. Many prominent members of the bitcoin community, including Andresen, who handed control of the software to Dutch coder Wladimir van der Laan in 2014, believe bitcoin transactions are too slow and too expensive. Although transaction fees are optional, failing to include a high enough fee could mean your transaction won’t be processed for hours or days. In December 2017, transaction fees averaged $20 to $30, according to the site BitInfoCharts. That makes bitcoin impractical for many daily transactions, such as buying lunch.
Developers have proposed technical solutions for this problem. But the plan favored by Andresen and company would require bitcoin users to switch to a new version of the software, and so far miners have been reluctant to do so. That’s led to the creation of several alternate versions of the bitcoin software, known as “hard forks,” each competing to lure both miners and users away from official version. Some, like Bitcoin Cash, have attracted miners and investors, but none is close to displacing the original. Meanwhile, many other “cryptocurrencies” have emerged, borrowing heavily from the core ideas behind bitcoin but with many differences (see The WIRED Guide to Blockchain).
What’s Next for Bitcoin
The future of bitcoin depends on three major questions. First, whether any of the hard forks or the hundreds of competing cryptocurrencies will supplant it, and, if so, when. Second, whether the sky-high valuations can last. And third, whether bitcoins will ever be used as currency for day-to-day transactions. The answer to the third question hinges in large part on the first two.
One thing holding bitcoin back as a currency is the expense and time lag involved in processing transactions. Emin Gun Sirer, a professor and cryptography researcher at Cornell University, estimates that the bitcoin network typically processes a little more than three transactions per second. By comparison, the Visa credit-card network processes around 3,674 transactions per second. Worse, bitcoin transaction confirmations can take hours or even days.
The First Real-World Bitcoin Transaction
There were few places to spend bitcoin during its early years, before the black markets that made the currency famous emerged. The first time someone actually used bitcoin to buy something is widely considered to have been May 22, 2010. Programmer Laszlo Hanyecz paid 10,000 bitcoin (worth around $41 at the time) to have two pizzas delivered to his house. Those 10,000 bitcoin are worth millions now. “I don’t feel bad about it,†Hanyecz told WIRED in 2011, when the coins would have sold for $272,329. “The pizza was really good.â€
In addition to the hard forks of bitcoin, there are now countless alternative cryptocurrencies, sometimes called “alt-coins,†that aim to solve some of bitcoin’s shortcomings. Litecoin, for example, is designed to process transactions more quickly than bitcoin, while Monero focuses on creating a more private alternative. None trade for as much as bitcoin, but several sell for hundreds of dollars.
If one of the bitcoin variants or alternatives can solve its main problems, and win over users and miners, that currency would become much more suitable for day-to-day use. It’s also possible that the developers behind the official version of bitcoin will find a way to make the network cheaper and faster while maintaining compatibility with old versions of the software. The maintainers of the original bitcoin software platform are working on a solution called the “Lightning Network†that would shift many transactions to “private channels,†to boost speed and reduce costs.
And then there’s the environmental impact. Critics argue that mining bitcoin is an enormous waste of electricity because they don’t have any intrinsic value.
Even if the technical issues of cost and performance are solved, there’s still the question of volatility. Businesses and consumers can exchange dollars for goods and services with the confidence that those dollars will be worth the same amount in three weeks when the rent is due. But bitcoin has proven far more volatile than most other assets, according to a study conducted by the bitcoin wallet company Coinbase. For example, On November 29, bitcoin surged from just under $10,000 to well over $11,000 before sinking back to about where it started the day.
The founders of Coinbase have argued that derivative markets could help users cope with the volatility by allowing participants to essentially buy insurance that pays out if the price of bitcoin drops. That might not reduce the volatility, but it might reduce the risk of accepting bitcoin as payment. In 2017, US regulators cleared the Chicago Mercantile Exchange and the Chicago Board Options Futures Exchange, the world’s largest derivatives exchanges, to offer bitcoin futures. But it’s too early to tell if it will make bitcoin more acceptable to retailers.
Bitcoin has come an enormous way since its origins as a paper by a pseudonymous author. But it still has a long way to go to fulfill its creator’s dream.
Bitcoin Is Splitting in Two. Now What? A deeper dive on why some bitcoin community leaders want to switch to new, more efficient, versions of the software, and their struggle to win over miners and users.
The Hard Math Behind Bitcoin’s Global Warming Problem A 2017 report estimated that bitcoin uses more electricity than the country of Serbia. Here we explain how bitcoin mining works, why it uses so much energy, and why that’s so hard to change.
The Rise and Fall of Silk Road, part 1 and part 2 Bitcoin isn’t always, or even primarily, used for shady purposes. But the online, illegal drug marketplace Silk Road is what put it on the map.
The Inside Story of Mt. Gox, Bitcoin’s $460 Million Disaster Mt. Gox’s bankruptcy caused the first major bitcoin crash and served as a hard reminder that banks are regulated and insured for a reason. This is the Mt. Gox story, from its beginnings as a planned Magic: The Gathering card-trading site to its emergence as the biggest bitcoin trading platform to its downfall.
‘I Forgot My PIN’: An Epic Tale of Losing $30,000 in Bitcoin Mark Frauenfelder forgot the PIN for his digital bitcoin wallet. The story of recovering his $30,000 worth of cryptocurrency illustrates both the perils of a decentralized network where no one can reset your passwords.
from Wired Top Stories http://ift.tt/2nxm3A4
via IFTTT
In early 2014, Srikanth Thirumalai met with Amazon CEO Jeff Bezos. Thirumalai, a computer scientist who’d left IBM in 2005 to head Amazon’s recommendations team, had come to propose a sweeping new plan for incorporating the latest advances in artificial intelligence into his division.
He arrived armed with a “six-pager.†Bezos had long ago decreed that products and services proposed to him must be limited to that length, and include a speculative press release describing the finished product, service, or initiative. Now Bezos was leaning on his deputies to transform the company into an AI powerhouse. Amazon’s product recommendations had been infused with AI since the company’s very early days, as had areas as disparate as its shipping schedules and the robots zipping around its warehouses. But in recent years, there has been a revolution in the field; machine learning has become much more effective, especially in a supercharged form known as deep learning. It has led to dramatic gains in computer vision, speech, and natural language processing.
In the early part of this decade, Amazon had yet to significantly tap these advances, but it recognized the need was urgent. This era’s most critical competition would be in AI—Google, Facebook, Apple, and Microsoft were betting their companies on it—and Amazon was falling behind. “We went out to every [team] leader, to basically say, ‘How can you use these techniques and embed them into your own businesses?’†says David Limp, Amazon’s VP of devices and services.
Thirumalai took that to heart, and came to Bezos for his annual planning meeting with ideas on how to be more aggressive in machine learning. But he felt it might be too risky to wholly rebuild the existing system, fine-tuned over 20 years, with machine-learning techniques that worked best in the unrelated domains of image and voice recognition. “No one had really applied deep learning to the recommendations problem and blown us away with amazingly better results,†he says. “So it required a leap of faith on our part.†Thirumalai wasn’t quite ready—but Bezos wanted more. So Thirumalai shared his edgier option of using deep learning to revamp the way recommendations worked. It would require skills that his team didn’t possess, tools that hadn’t been created, and algorithms that no one had thought of yet. Bezos loved it (though it isn’t clear whether he greeted it with his trademark hyena-esque laugh), so Thirumalai rewrote his press release and went to work.
Srikanth Thirumalai, VP of Amazon Search, was among the leaders tasked with overhauling Amazon’s software with advanced machine learning.
Ian C. Bates
Thirumalai was only one of a procession of company leaders who trekked to Bezos a few years ago with six-pagers in hand. The ideas they proposed involved completely different products with different sets of customers. But each essentially envisioned a variation of Thirumalai’s approach: transforming part of Amazon with advanced machine learning. Some of them involved rethinking current projects, like the company’s robotics efforts and its huge data-center business, Amazon Web Services (AWS). Others would create entirely new businesses, like a voice-based home appliance that would become the Echo.
The results have had an impact far beyond the individual projects. Thirumalai says that at the time of his meeting, Amazon’s AI talent was segregated into isolated pockets. “We would talk, we would have conversations, but we wouldn’t share a lot of artifacts with each other because the lessons were not easily or directly transferable,†he says. They were AI islands in a vast engineering ocean. The push to overhaul the company with machine learning changed that.
While each of those six-pagers hewed to Amazon’s religion of “single-threaded†teams—meaning that only one group “owns†the technology it uses—people started to collaborate across projects. In-house scientists took on hard problems and shared their solutions with other groups. Across the company, AI islands became connected. As Amazon’s ambition for its AI projects grew, the complexity of its challenges became a magnet for top talent, especially those who wanted to see the immediate impact of their work. This compensated for Amazon’s aversion to conducting pure research; the company culture demanded that innovations come solely in the context of serving its customers.
Amazon loves to use the word flywheel to describe how various parts of its massive business work as a single perpetual motion machine. It now has a powerful AI flywheel, where machine-learning innovations in one part of the company fuel the efforts of other teams, who in turn can build products or offer services to affect other groups, or even the company at large. Offering its machine-learning platforms to outsiders as a paid service makes the effort itself profitable—and in certain cases scoops up yet more data to level up the technology even more.
It took a lot of six-pagers to transform Amazon from a deep-learning wannabe into a formidable power. The results of this transformation can be seen throughout the company—including in a recommendations system that now runs on a totally new machine-learning infrastructure. Amazon is smarter in suggesting what you should read next, what items you should add to your shopping list, and what movie you might want to watch tonight. And this year Thirumalai started a new job, heading Amazon search, where he intends to use deep learning in every aspect of the service.
“If you asked me seven or eight years ago how big a force Amazon was in AI, I would have said, ‘They aren’t,’†says Pedro Domingos, a top computer science professor at the University of Washington. “But they have really come on aggressively. Now they are becoming a force.â€
Maybe the force.
The Alexa Effect
The flagship product of Amazon’s push into AI is its breakaway smart speaker, the Echo, and the Alexa voice platform that powers it. These projects also sprang from a six-pager, delivered to Bezos in 2011 for an annual planning process called Operational Plan One. One person involved was an executive named Al Lindsay, an Amazonian since 2004, who had been asked to move from his post heading the Prime tech team to help with something totally new. “A low-cost, ubiquitous computer with all its brains in the cloud that you could interact with over voice—you speak to it, it speaks to you,†is how he recalls the vision being described to him.
But building that system—literally an attempt to realize a piece of science fiction, the chatty computer from Star Trek—required a level of artificial intelligence prowess that the company did not have on hand. Worse, of the very few experts who could build such a system, even fewer wanted to work for Amazon. Google and Facebook were snapping up the top talent in the field. “We were the underdog,†Lindsay, who is now a VP, says.
Al Lindsay, the VP of Amazon Alexa Engine, says Amazon was the underdog when trying to recruit AI experts to design and build its voice platform.
Ian C. Bates
“Amazon had a bit of a bad image, not friendly to people who were research oriented,†says Domingos, the University of Washington professor. The company’s relentless focus on the customer, and its culture of scrappiness, did not jibe with the pace of academia or cushy perks of competitors. “At Google you’re pampered,†Domingos says. “At Amazon you set up your computer from parts in the closet.†Worse, Amazon had a reputation as a place where innovative work was kept under corporate wraps. In 2014, one of the top machine-learning specialists, Yann LeCun, gave a guest lecture to Amazon’s scientists in an internal gathering. Between the time he was invited and the event itself, LeCun accepted a job to lead Facebook’s research effort, but he came anyway. As he describes it now, he gave his talk in an auditorium of about 600 people and then was ushered into a conference room where small groups came in one by one and posed questions to him. But when he asked questions of them, they were unresponsive. This turned off LeCun, who had chosen Facebook in part because it agreed to open-source much of the work of its AI team.
Because Amazon didn’t have the talent in-house, it used its deep pockets to buy companies with expertise. “In the early days of Alexa, we bought many companies,†Limp says. In September 2011, it snapped up Yap, a speech-to-text company with expertise in translating the spoken word into written language. In January 2012, Amazon bought Evi, a Cambridge, UK, AI company whose software could respond to spoken requests like Siri does. And in January 2013, it bought Ivona, a Polish company specializing in text-to-speech, which provided technology that enabled Echo to talk.
But Amazon’s culture of secrecy hampered its efforts to attract top talent from academia. One potential recruit was Alex Smola, a superstar in the field who had worked at Yahoo and Google. “He is literally one of the godfathers of deep learning,†says Matt Wood, the general manager of deep learning and AI at Amazon Web Services. (Google Scholar lists more than 90,000 citations of Smola’s work.) Amazon execs wouldn’t even reveal to him or other candidates what they would be working on. Smola rejected the offer, choosing instead to head a lab at Carnegie Mellon.
Director of Alexa Ruhi Sarikaya and VP of Amazon Alexa Engine Al Lindsay led an effort to create not only the Echo line of smart speakers, but also a voice service that could work with other company products.
Ian C. Bates
“Even until right before we launched there was a headwind,†Lindsay says. “They would say, ‘Why would I want to work at Amazon—I’m not interested in selling people products!’â€
Amazon did have one thing going for it. Since the company works backward from an imagined final product (thus the fanciful press releases), the blueprints can include features that haven’t been invented yet. Such hard problems are irresistible to ambitious scientists. The voice effort in particular demanded a level of conversational AI—nailing the “wake word†(“Hey Alexa!â€), hearing and interpreting commands, delivering non-absurd answers—that did not exist.
That project, even without the specifics on what Amazon was building, helped attract Rohit Prasad, a respected speech-recognition scientist at Boston-based tech contractor Raytheon BBN. (It helped that Amazon let him build a team in his hometown.) He saw Amazon’s lack of expertise as a feature, not a bug. “It was green fields here,†he says. “Google and Microsoft had been working on speech for years. At Amazon we could build from scratch and solve hard problems.†As soon as he joined in 2013, he was sent to the Alexa project. “The device existed in terms of the hardware, but it was very early in speech,†he says.
The trickiest part of the Echo—the problem that forced Amazon to break new ground and in the process lift its machine-learning game in general—was something called far field speech recognition. It involves interpreting voice commands spoken some distance from the microphones, even when they are polluted with ambient noise or other aural detritus. One challenging factor was that the device couldn’t waste any time cogitating about what you said. It had to send the audio to the cloud and produce an answer quickly enough that it felt like a conversation, and not like those awkward moments when you’re not sure if the person you’re talking to is still breathing. Building a machine-learning system that could understand and respond to conversational queries in noisy conditions required massive amounts of data—lots of examples of the kinds of interactions people would have with their Echos. It wasn’t obvious where Amazon might get such data.
Various Amazon devices and third-party products now use the Alexa voice service. Data collected through Alexa helps improve the system and supercharges Amazon’s broader AI efforts.
Ian C. Bates
Far-field technology had been done before, says Limp, the VP of devices and services. But “it was on the nose cone of Trident submarines, and it cost a billion dollars.†Amazon was trying to implement it in a device that would sit on a kitchen counter, and it had to be cheap enough for consumers to spring for a weird new gadget. “Nine out of 10 people on my team thought it couldn’t be done,†Prasad says. “We had a technology advisory committee of luminaries outside Amazon—we didn’t tell them what we were working on, but they said, ‘Whatever you do, don’t work on far field recognition!’â€
Prasad’s experience gave him confidence that it could be done. But Amazon did not have an industrial-strength system in place for applying machine learning to product development. “We had a few scientists looking at deep learning, but we didn’t have the infrastructure that could make it production-ready,†he says. The good news was that all the pieces were there at Amazon—an unparalleled cloud service, data centers loaded with GPUs to crunch machine-learning algorithms, and engineers who knew how to move data around like fireballs.
His team used those parts to create a platform that was itself a valuable asset, beyond its use in fulfilling the Echo’s mission. “Once we developed Echo as a far-field speech recognition device, we saw the opportunity to do something bigger—we could expand the scope of Alexa to a voice service,†says Alexa senior principal scientist Spyros Matsoukas, who had worked with Prasad at Raytheon BBN. (His work there had included a little-known Darpa project called Hub4, which used broadcast news shows and intercepted phone conversations to advance voice recognition and natural language understanding—great training for the Alexa project.) One immediate way they extended Alexa was to allow third-party developers to create their own voice-technology mini-applications—dubbed “skillsâ€â€”to run on the Echo itself. But that was only the beginning.
Spyros​ ​Matsoukas​, a senior principal scientist at Amazon, helped turn Alexa into a force for strengthening Amazon’s company-wide culture around AI.
Adam Glanzman
By breaking out Alexa beyond the Echo, the company’s AI culture started to coalesce. Teams across the company began to realize that Alexa could be a useful voice service for their pet projects too. “So all that data and technology comes together, even though we are very big on single-threaded ownership,†Prasad says. First other Amazon products began integrating into Alexa: When you speak into your Alexa device you can access Amazon Music, Prime Video, your personal recommendations from the main shopping website, and other services. Then the technology began hopscotching through other Amazon domains. “Once we had the foundational speech capacity, we were able to bring it to non-Alexa products like Fire TV, voice shopping, the Dash wand for Amazon fresh, and, ultimately, AWS,†Lindsay says.
The AI islands within Amazon were drawing closer.
Another pivotal piece of the company’s transformation clicked into place once millions of customers (Amazon won’t say exactly how many) began using the Echo and the family of other Alexa-powered devices. Amazon started amassing a wealth of data—quite possibly the biggest collection of interactions of any conversation-driven device ever. That data became a powerful lure for potential hires. Suddenly, Amazon rocketed up the list of places where those coveted machine-learning experts might want to work. “One of the things that made Alexa so attractive to me is that once you have a device in the market, you have the resource of feedback. Not only the customer feedback, but the actual data that is so fundamental to improving everything—especially the underlying platform,†says Ravi Jain, an Alexa VP of machine learning who joined the company last year.
So as more people used Alexa, Amazon got information that not only made that system perform better but supercharged its own machine-learning tools and platforms—and made the company a hotter destination for machine-learning scientists.
Swami Sivasubramanian, VP of AI, AWS was among the first to realize the business implications of integrating AI tools into the company’s cloud services.
Ian C. Bates
At his next Jeff Bezos review he came armed with an epic six-pager. On one level, it was a blueprint for adding machine-learning services to AWS. But Sivasubramanian saw it as something broader: a grand vision of how AWS could become the throbbing center of machine-learning activity throughout all of techdom.
In a sense, offering machine learning to the tens of thousands of Amazon cloud customers was inevitable. “When we first put together the original business plan for AWS, the mission was to take technology that was only in reach of a small number of well-funded organizations and make it as broadly distributed as possible,†says Wood, the AWS machine-learning manager. “We’ve done that successfully with computing, storage, analytics, and databases—and we’re taking the exact same approach with machine learning.†What made it easier was that the AWS team could draw on the experience that the rest of the company was accumulating.
AWS’s Amazon Machine Learning, first offered in 2015, allows customers like C-Span to set up a private catalog of faces, Wood says. Zillow uses it to estimate house prices. Pinterest employs it for visual search. And several autonomous driving startups are using AWS machine learning to improve products via millions of miles of simulated road testing.
In 2016, AWS released new machine-learning services that more directly drew on the innovations from Alexa—a text-to-speech component called Polly and a natural language processing engine called Lex. These offerings allowed AWS customers, which span from giants like Pinterest and Netflix to tiny startups, to build their own mini Alexas. A third service involving vision, Rekognition, drew on work that had been done in Prime Photos, a relatively obscure group at Amazon that was trying to perform the same deep-learning wizardry found in photo products by Google, Facebook, and Apple.
These machine-learning services are both a powerful revenue generator and key to Amazon’s AI flywheel, as customers as disparate as NASA and the NFL are paying to get their machine learning from Amazon. As companies build their vital machine-learning tools inside AWS, the likelihood that they will move to competing cloud operations becomes ridiculously remote. (Sorry, Google, Microsoft, or IBM.) Consider Infor, a multibillion-dollar company that creates business applications for corporate customers. It recently released an extensive new application called Coleman (named after the NASA mathematician in Hidden Figures) that allows its customers to automate various processes, analyze performance, and interact with data all through a conversational interface. Instead of building its own bot from scratch, it uses AWS’s Lex technology. “Amazon is doing it anyway, so why would we spend time on that? We know our customers and we can make it applicable to them,†says Massimo Capoccia, a senior VP of Infor.
AWS’s dominant role in the ether also gives it a strategic advantage over competitors, notably Google, which had hoped to use its machine-learning leadership to catch up with AWS in cloud computing. Yes, Google may offer customers super-fast, machine-learning-optimized chips on its servers. But companies on AWS can more easily interact with—and sell to—firms that are also on the service. “It’s like Willie Sutton saying he robs banks because that’s where the money is,†says DigitalGlobe CTO Walter Scott about why his firm uses Amazon’s technology. “We use AWS for machine learning because that’s where our customers are.â€
Last November at the AWS re:Invent conference, Amazon unveiled a more comprehensive machine-learning prosthetic for its customers: SageMaker, a sophisticated but super easy-to-use platform. One of its creators is none other than Alex Smola, the machine-learning superstar with 90,000 academic citations who spurned Amazon five years ago. When Smola decided to return to industry, he wanted to help create powerful tools that would make machine learning accessible to everyday software developers. So he went to the place where he felt he’d make the biggest impact. “Amazon was just too good to pass up,†he says. “You can write a paper about something, but if you don’t build it, nobody will use your beautiful algorithm,†he says.
When Smola told Sivasubramanian that building tools to spread machine learning to millions of people was more important than publishing one more paper, he got a nice surprise. “You can publish your paper, too!†Sivasubramanian said. Yes, Amazon is now more liberal in permitting its scientists to publish. “It’s helped quite a bit with recruiting top talent as well as providing visibility of what type of research is happening at Amazon,†says Spyros Matsoukas, who helped set guidelines for a more open stance.
It’s too early to know if the bulk of AWS’s million-plus customers will begin using SageMaker to build machine learning into their products. But every customer that does will find itself heavily invested in Amazon as its machine-learning provider. In addition, the platform is sufficiently sophisticated that even AI groups within Amazon, including the Alexa team, say they intend to become SageMaker customers, using the same toolset offered to outsiders. They believe it will save them a lot of work by setting a foundation for their projects, freeing them to concentrate on the fancier algorithmic tasks.
Even if only some of AWS’s customers use SageMaker, Amazon will find itself with an abundance of data about how its systems perform (excluding, of course, confidential information that customers keep to themselves). Which will lead to better algorithms. And better platforms. And more customers. The flywheel is working overtime.
AI Everywhere
With its machine learning overhaul in place, the company’s AI expertise is now distributed across its many teams—much to the satisfaction of Bezos and his consiglieri. While there is no central office of AI at Amazon, there is a unit dedicated to the spread and support of machine learning, as well as some applied research to push new science into the company’s projects. The Core Machine Learning Group is led by Ralf Herbrich, who worked on the Bing team at Microsoft and then served a year at Facebook, before Amazon lured him in 2012. “It’s important that there’s a place that owns this community†within the company, he says. (Naturally, the mission of the team was outlined in an aspirational six-pager approved by Bezos.)
Part of his duties include nurturing Amazon’s fast-growing machine-learning culture. Because of the company’s customer-centric approach—solving problems rather than doing blue-sky research—Amazon execs do concede that their recruiting efforts will always tilt towards those interested in building things rather than those chasing scientific breakthroughs. Facebook’s LeCun puts it another way: “You can do quite well by not leading the intellectual vanguard.â€
But Amazon is following Facebook and Google’s lead in training its workforce to become adept at AI. It runs internal courses on machine-learning tactics. It hosts a series of talks from its in-house experts. And starting in 2013, the company has hosted an internal machine-learning conference at its headquarters every April, a kind of Amazon-only version of NIPS, the premier academic machine-learning-palooza. “When I started, the Amazon machine-learning conference was just a couple hundred people; now it’s in the thousands,†Herbrich says. “We don’t have the capacity in the largest meeting room in Seattle, so we hold it there and stream it to six other meeting rooms on the campus.†One Amazon exec remarks that if it gets any bigger, instead of calling it an Amazon machine-learning event, it should just be called Amazon.
Herbrich’s group continues to push machine learning into everything the company attempts. For example, the fulfillment teams wanted to better predict which of the eight possible box sizes it should use with a customer order, so they turned to Herbrich’s team for help. “That group doesn’t need its own science team, but it needed these algorithms and needed to be able to use them easily,†he says. In another example, David Limp points to a transformation in how Amazon predicts how many customers might buy a new product. “I’ve been in consumer electronics for 30 years now, and for 25 of those forecasting was done with [human] judgment, a spreadsheet, and some Velcro balls and darts,†he says. “Our error rates are significantly down since we’ve started using machine learning in our forecasts.â€
Still, sometimes Herbrich’s team will apply cutting-edge science to a problem. Amazon Fresh, the company’s grocery delivery service, has been operating for a decade, but it needed a better way to assess the quality of fruits and vegetables—humans were too slow and inconsistent. His Berlin-based team built sensor-laden hardware and new algorithms that compensated for the inability of the system to touch and smell the food. “After three years, we have a prototype phase, where we can judge the quality more reliably†than before, he says.
Of course, such advances can then percolate throughout the Amazon ecosystem. Take Amazon Go, the deep-learning-powered cashier-less grocery store in its headquarters building that recently opened to the public. “As a customer of AWS, we benefit from its scale,†says Dilip Kumar, VP of Technology for Amazon Go. “But AWS is also a beneficiary.†He cites as an example Amazon Go’s unique system of streaming data from hundreds of cameras to track the shopping activities of customers. The innovations his team concocted helped influence an AWS service called Kinesis, which allows customers to stream video from multiple devices to the Amazon cloud, where they can process it, analyze it, and use it to further advance their machine learning efforts.
Even when an Amazon service doesn’t yet use the company’s machine-learning platform, it can be an active participant in the process. Amazon’s Prime Air drone-delivery service, still in the prototype phase, has to build its AI separately because its autonomous drones can’t count on cloud connectivity. But it still benefits hugely from the flywheel, both in drawing on knowledge from the rest of the company and figuring out what tools to use. “We think about this as a menu—everybody is sharing what dishes they have,†says Gur Kimchi, VP of Prime Air. He anticipates that his team will eventually have tasty menu offerings of its own. “The lessons we’re learning and problems we’re solving in Prime Air are definitely of interest to other parts of Amazon,†he says.
In fact, it already seems to be happening. “If somebody’s looking at an image in one part of the company, like Prime Air or Amazon Go, and they learn something and create an algorithm, they talk about it with other people in the company,†says Beth Marcus, a principal scientist at Amazon robotics. “And so someone in my team could use it to, say, figure out what’s in an image of a product moving through the fulfillment center.â€
Beth Marcus​, senior principal technologist at Amazon Robotics, has seen the benefits of collaborating with the company’s growing pool of AI experts.
Adam Glanzman
Is it possible for a company with a product-centered approach to eclipse the efforts of competitors staffed with the superstars of deep learning? Amazon’s making a case for it. “Despite the fact they’re playing catchup, their product releases have been incredibly impressive,†says Oren Etzioni, CEO of the Allen Institute for Artificial Intelligence. “They’re a world-class company and they’ve created world-class AI products.â€
The flywheel keeps spinning, and we haven’t seen the impact of a lot of six-pager proposals still in the pipeline. More data. More customers. Better platforms. More talent.
Alexa, how is Amazon doing in AI?
The answer? Jeff Bezos’s braying laugh.
from Wired Top Stories http://ift.tt/2ntt71a
via IFTTT
The algorithm DroNet allows drones to fly completely by themselves through the streets of a city and in indoor environments. It produces two outputs for each single input image: a steering angle to keep the drone navigating while avoiding obstacles, and a collision probability to let the drone recognize dangerous situations and promptly react to them.
from NASA Tech Briefs http://ift.tt/2nvnWxR
via IFTTT
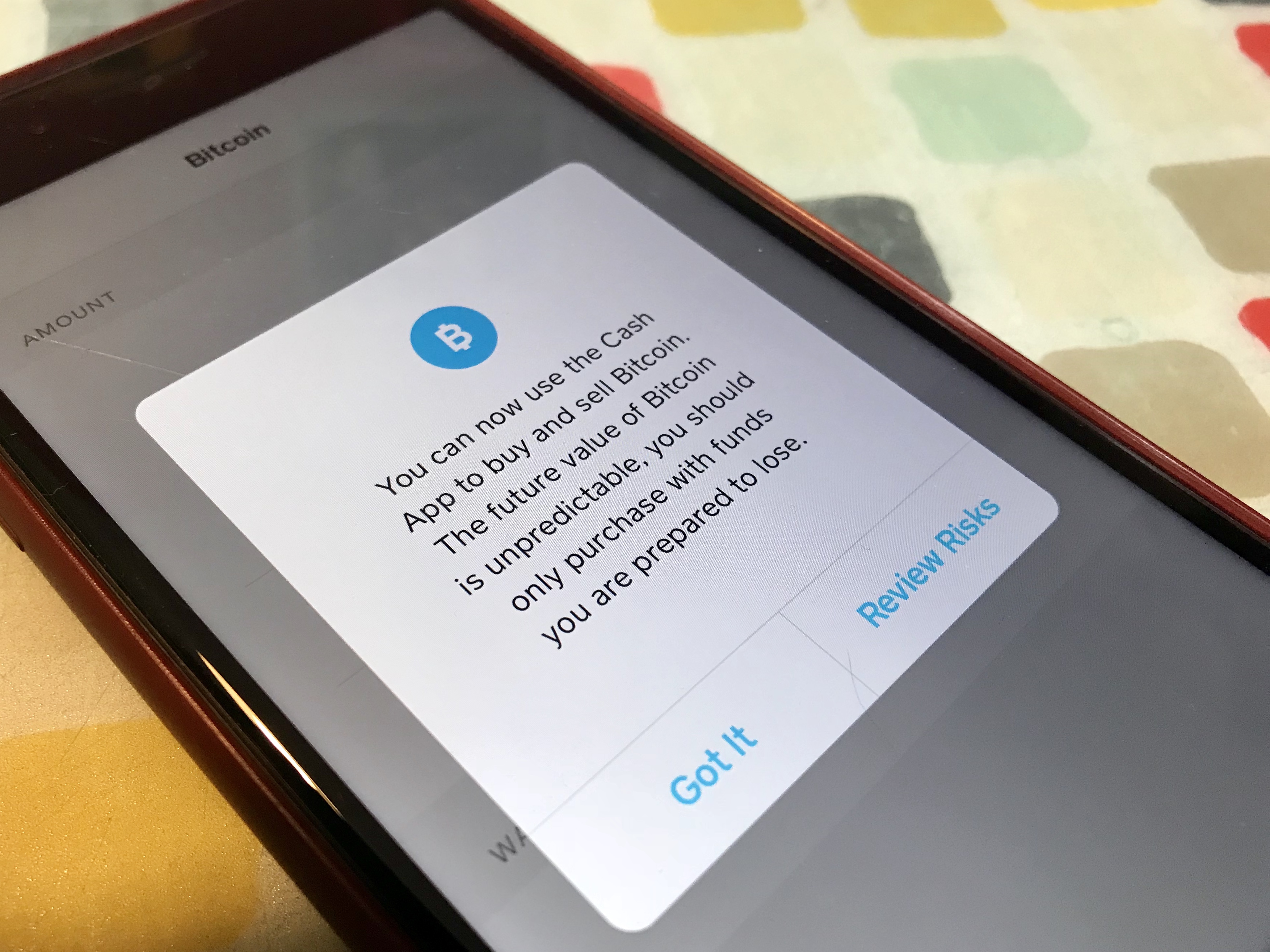
Square’s Cash App has been helping people send and receive money without fees for a while now. Originally an money-by-email service, Cash App has grown into a more robust offering with its own prepaid Visa card. The company has been testing buying and selling Bitcoin via the app, as well, and has finally made it official.
Blockchaiiiiinnnnn! You can now buy and sell Bitcoin instantly with the Cash App!
The feature is available to most everyone who uses Cash App, unless they’re in New York, Georgia, Hawaii or Wyoming. The company promises that it’s working on it. This does seem to be a pretty simple way to get into owning Bitcoin, though Square warns that the cryptocurrency’s price is "volatile and unpredictable." While the company won’t add additional fees when you purchase Bitcoin through its app, it calculates the price when buying based on a quoted mid-market price and margin, which could be different when selling. You’ll also be limited to up to $10,000 worth of Bitcoin per week, so be sure to plan accordingly.
We aren’t yet rolled out in New York, Georgia, Hawaii, or Wyoming – but we’re working on it! Stay tuned.
Waymo’s vehicles drove 2 million miles in self-driving mode across 25 cities in 2017, putting its total autonomous miles to 4 million. It accelerated its testing to prepare for its ride-hailing fleet’s launch this year, allowing it to "gather as much data as possible in order to improve [its] technology." According to its annual report submitted to the government of California, Waymo drove 352,545 of those miles in The Golden State from December 2016 to November 2017. Within that period, the company reported a total of 63 disengagements (instances wherein the human test driver had to step in), which means its vehicles drove an average of 5,595 miles for every disengagement.
While its disengagement rate only fell 0.02 points from 0.20 to 0.18 over the twelve-month period, all these numbers indicate that Waymo is still ahead of its peers. It’s done the most extensive testing among all the companies with California permits, and as The Atlantic noted, only GM’s Cruise division comes close when it comes to autonomous mileage. Cruise vehicles racked up 125,000 miles on San Francisco’s streets without the help of a human driver and reported a yearly average of 1,254 miles per disengagement. We’re guessing GM also has plans to expand its testing efforts this year, considering it’s aiming to start selling cars without steering wheels in 2019.
Among all the causes of disengagement Waymo mentioned, "unwanted maneuver of the vehicle" topped the list with 19 instances, followed by "perception discrepancy" with 16. It’s worth noting, however, that most of those instances happened in the earlier part of the 12-month period, suggesting that the company’s technology improved tremendously in the second half of 2017.
On Wednesday evening, a couple of hours after the Falcon 9 rocket had successfully deployed a satellite into geostationary transfer orbit, SpaceX founder Elon Musk shared a rather amazing photo on Twitter. “This rocket was meant to test very high retrothrust landing in water so it didn’t hurt the droneship, but amazingly it has survived,” he wrote. “We will try to tow it back to shore.” In other words, a rocket that SpaceX had thought would be lost after it made an experimental, high-thrust landing somehow survived after hitting the ocean.
This was amazing for a couple of reasons. First of all, when the first stage of a rocket hits water after a launch, it typically explodes. (This can be seen in some of the early water landing attempts shown in a blooper reel released by the company). A rocket should not survive impact because it will rupture the relatively thin aluminum-lithium tanks that separate fuel and oxidizer. These tanks are built to withstand the axial force of a vertical launch, but not a crash into the ocean.
In this case, that did not happen. Perhaps the rocket descended such that the engines and lower end of the booster were submerged, before the 40-meter tall first stage tipped over—gently. Hopefully, at some point, SpaceX will release video from the on-board camera or other assets in the Atlantic Ocean that observed the landing on Wednesday evening.
Another reason to be surprised at the landing is the fact that the rocket performed a “three engine” landing burn. Normally, during the last part of a Falcon 9 landing, the central engine alone fires to slow the rocket for its final descent. (See, for example, here). In this case the rocket performed what Musk called a “very high retrothrust landing,” which means that three engines fired instead of one to triple the deceleration force.
This is significant because three engines firing instead of one greatly increases the gravitational force exerted on the structure of the approximately 27-ton rocket. Calculations by amateur enthusiasts on Reddit suggest that the Falcon 9 booster underwent approximately 10gs of force compared to the normal 3gs, in the seconds before landing. The upside of landing with three engines is that a booster only has to fire them for a short amount of time relative to a single engine deceleration burn, and therefore it uses considerably less fuel.
In 1982 the towing ship, Liberty, tows a recovered solid rocket booster from for the STS-5 mission to Port Canaveral, Florida.
NASA
It is not clear how SpaceX will attempt to tow the rocket to shore. The company’s Atlantic Ocean-based drone ship, “Of Course I Still Love You,” will be in service during the next week to catch the central core of the Falcon Heavy launch, tentatively scheduled for Tuesday, February 6. Perhaps the company will take a page from the playbook of NASA, which recovered the space shuttle’s larger solid-rocket boosters, with tugboats.






{kind=link}