If you try out Intel’s AI Playground, which incorporates everything from AI art to an LLM chatbot to even text-to-video in a single app, you might think: Wow! OK! An all-in-one local AI app that does everything is worth trying out! And it is… except that it’s made for just a small slice of Intel’s own products.
Quite simply, no single AI app has emerged as the “Amazon” of AI, doing everything you’d want in a single service or site. You can use a tool like Adobe Photoshop or Firefly to perform sophisticated image generations and editing, but chatting is out. ChatGPT or Google Gemini can converse with you, even generating images, but to a limited extent.
Most of these services require you to hopscotch back and forth between sites, however, and can cost money for a subscription. Intel’s AI Playground merges all of these inside a single, well-organized app that runs locally (and entirely privately) on your PC and it’s all for free.
Should I let you in on the catch? I suppose I have to. AI Playground is a showcase for Intel’s Core Ultra processors, including its CPUs and GPUs–the Core Ultra 100 (Meteor Lake) and Core Ultra 200 (Lunar Lake) chips, specifically. But it could be so, so much better if everyone could use it.
Mark Hachman / Foundry
Yes, I realize that some users are quite suspicious of AI. (There are even AI-generated news stories!) Others, however, have found that certain tasks in their daily life such as business email can be handed off to ChatGPT. AI is a tool, even if it can be used in ways we disagree with.
What’s in AI Playground?
AI Playground has three main areas, all designated by tabs on the top of the screen:
- Create: An AI image generator, which operates in either a default text-to-image mode, or in a “workflow” mode that uses a more sophisticated back end for higher-quality images
- Enhance: Here, you can edit your images, either upscaling them or altering them through generative AI
- Answer: A conventional AI chatbot, either as a standalone or with the ability to upload your own text documents
Each of those sections is what you might call self-sufficient, usable by itself. But in the upper right-hand corner is a settings or “gear” icon, which contains a terrific number of additional options, which are absolutely worth examining.
How to set up and install AI Playground
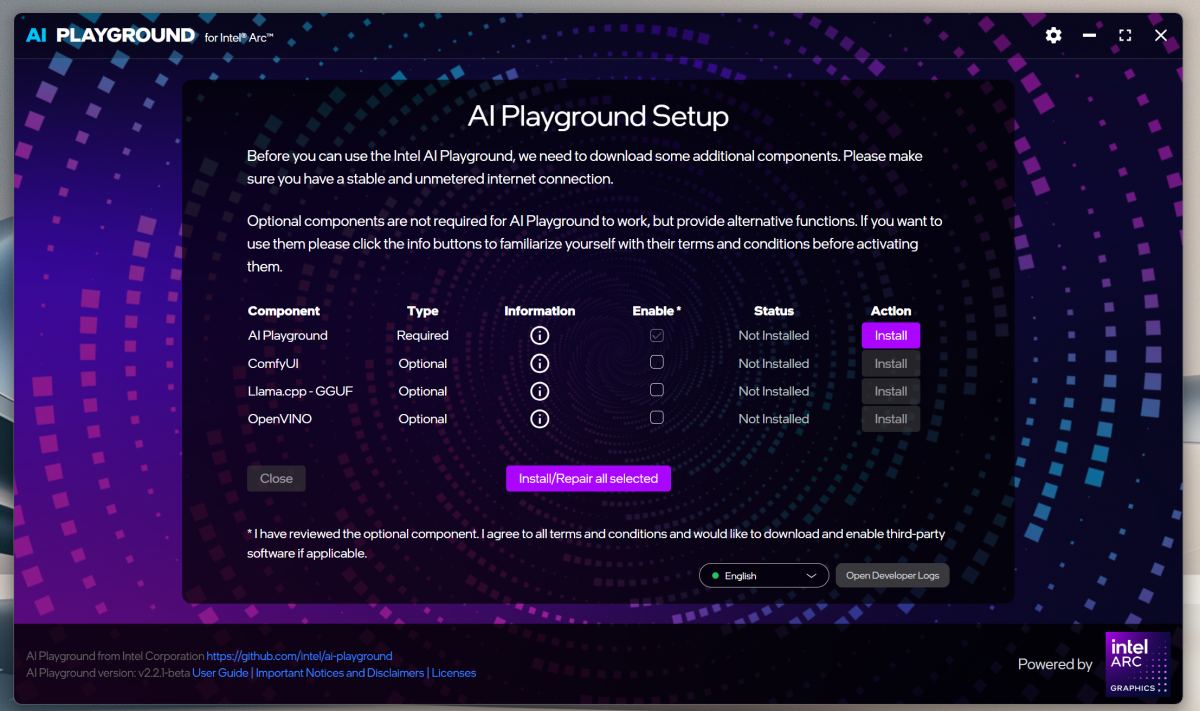
AI Playground’s strength is in its thoughtfulness, ease of use, and simplicity. If you’ve ever used a local AI application, you know that it can be rough. Some functions are content with just a command-line interface, which may require you to have a working knowledge of Python or GitHub. AI Playground was designed around the premise that it will take care of everything with just a single click. Documentation and explanations might be a little lacking in places, but AI Playground’s ease of use is unparalleled.
AI Playground can be downloaded from Intel’s AI Playground page. At press time, AI Playground was on version 2.2.1 beta.
Mark Hachman / Foundry
Note that the app and its back-end code require support for either a Core Ultra H (a “Meteor Lake” chip, the Core Ultra 200V) or either of the Intel Arc discrete GPUs, including the Alchemist and Battlemage parts. If you own a massive gaming laptop with a 14th-gen Intel Core chip or an Nvidia RTX 5090 GPU, you’re out of luck. Same with the Core Ultra 200H or “Arrow Lake.”
Since this is an “AI Playground,” you might think that the chip’s NPU would be used? Nope. All of these applications tap just the chip’s integrated GPU and I didn’t see the NPU being accessed once via Windows Task Manager.
Also, keep in mind that the GPU’s UMA frame buffer, the memory pool that’s shared between system memory and the integrated GPU, is what these AI models depend on. Intel’s integrated graphics shares half the available system memory with the system memory, as a unified memory architecture or UMA. Discrete GPUs have their own dedicated VRAM memory to pull from. The bottom line? You may not have enough video memory available to run every model.
Downloading the initial AI Playground application took about 680 megabytes on my machine. But that’s only the shell application. The models require an additional download, which will either be handled by the AI Installer application itself or may require you to click the “download” button itself.
The nice thing is that you don’t have to manage any of this. If AI Playground needs a model, it will tell you which one it requires and how much space on your hard drive it requires. None of the models I saw used more than 12GB of storage space and many much less. But if you want to try out a number of models, be prepared to download a couple dozen gigabytes or more.
Playing with AI Playground
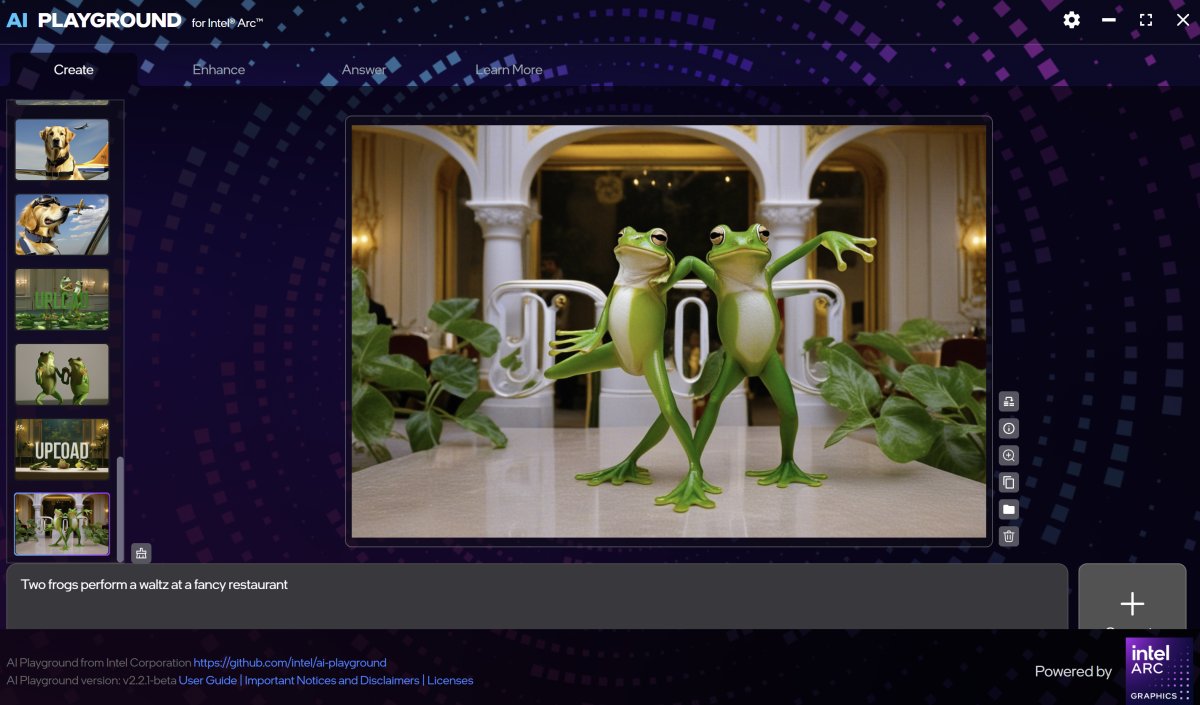
I’ve called Fooocus the easiest way to generate AI art on your PC. For its time, it was! And it works with just about any GPU, too. But AI Playground may be even easier. The tab opens with just the space for a prompt and nothing else.
Like most AI art, the prompt defines the image and you can get really detailed. Here’s an example: “Award winning photo of a high speed purple sports car, hyper-realism, racing fast over wet track at night. The license plate number is “B580?, motion blur, expansive glowing cityscape, neon lights…”
Mark Hachman / Foundry
Enter a prompt and AI Playground will draw four small images, which appear in a vertical column to the left. Each image progresses in a series of steps with 20 as the default. After the image is completed, some small icons will appear next to it with additional options, including importing it into the “Enhance” tab.
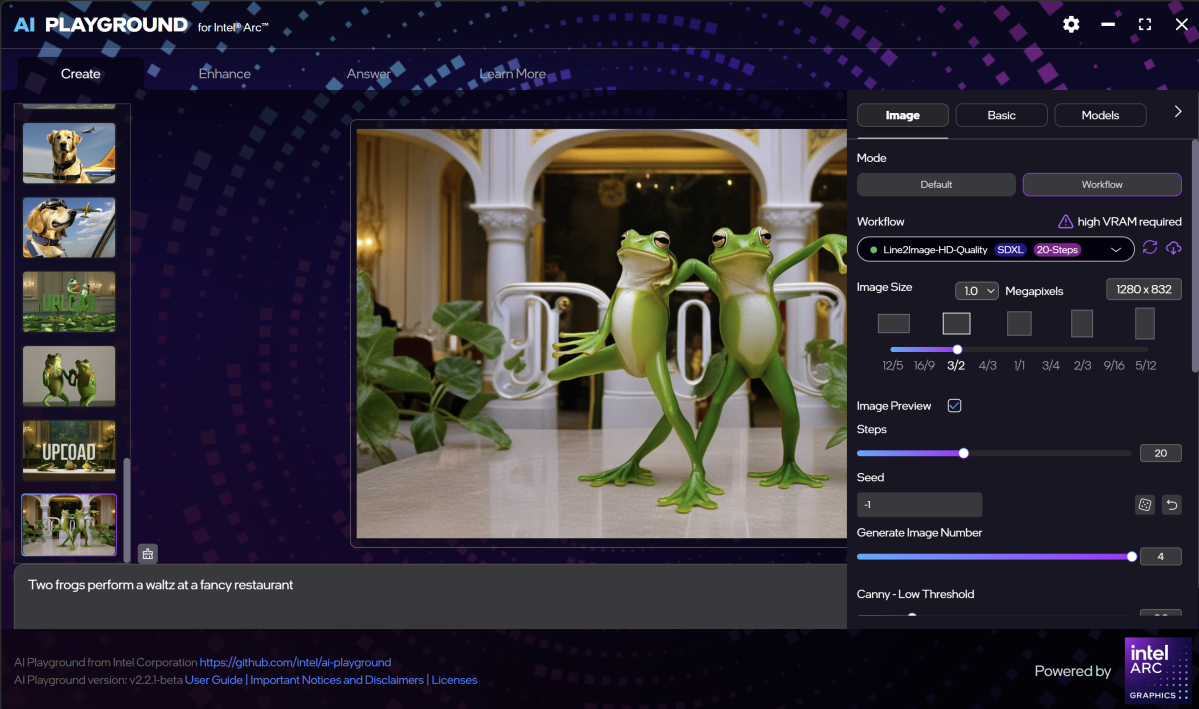
The Settings gear is where you can begin tweaking your output. You can select from either “Standard” or “HD” resolution, which adjusts the “Image Size” field. You can adjust image size and resolution, and tweak the format. The “HD” option requires you to download a different model, as does the ‘Workflow” option to the upper right, which adds workflows based on ComfyUI. Essentially, they’re just better looking images with the option to guide the output with a reference image or other workflow.

Mark Hachman / Foundry
For now, the default model can be adjusted via the “Manual” tab, which opens up two additional options. You’ll see a “negative prompt,” which excludes things that you put in, and a “Safe Check” to turn off gore and other disturbing images. By default, “NSFW” (Not Safe for Work) is added to the negative prompt.
Both the Safe Check and NSFW negative prompt only appear as options in the Default image generator and seem to be on by default elsewhere. It’s up to you whether or not to remove them. The Default model (Lykon/dreamshaper-8) has apparently been trained on nudity and celebrities, though I stuck to public figures for testing purposes.
Note that all of your AI-generated art stays local to your PC, though Intel (obviously) warns you not to use a person’s likeness without their permission.
There’s also a jaw-droppingly obvious bug that I can’t believe Intel didn’t catch. Creating an HD image often begins its images with “UPLOAD” projected over the image, and sometimes renders the final image with it on, too. Why? Because there’s a field to add a reference image and UPLOAD is right in the middle of it. Somehow, AI Playground used the UPLOAD font as part of the image.
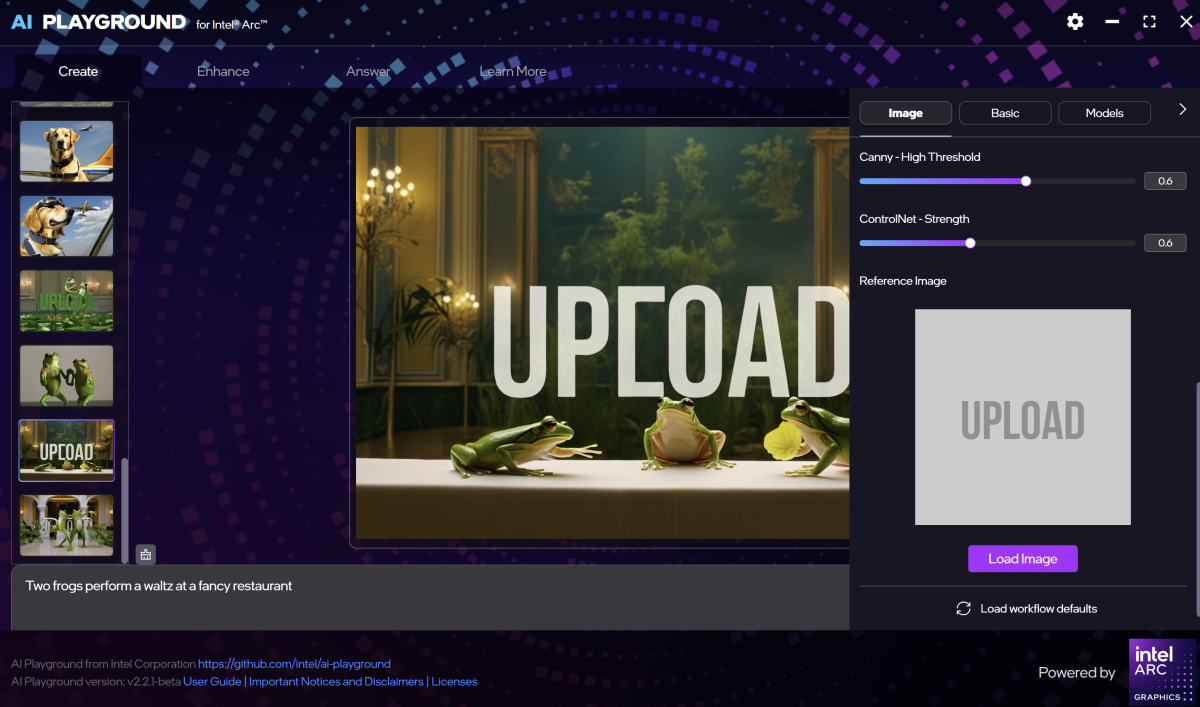
Mark Hachman / Foundry
Though my test machine was a Core Ultra 258V (Lunar Lake) with 32GB of RAM, an 896×576 image took 29 seconds to generate, with 25 rendering steps on the Default Mode. Using the Workflow (Line2-Image-HD-Quality) model at 1280×832 resolution and 20 steps, one image took two minutes 12 seconds to render. There’s also a Fast mode which should lower the rendering time, though I didn’t really like the output quality.
If you find an image you like, you can use the Enhance tab to upscale it. (Upscaling is being added to the Windows Photos app, which will eventually be made available to Copilot+ PCs using Intel Core Ultra 200 chips, too.) You can also use “inpainting,” which allows you to re-generate a portion of the screen, and “outpainting,” the technique which was used to “expand” the boundaries of the Mona Lisa painting, for example. You can also ask AI to tweak the image itself, though I had problems trying to generate a satisfactory result.
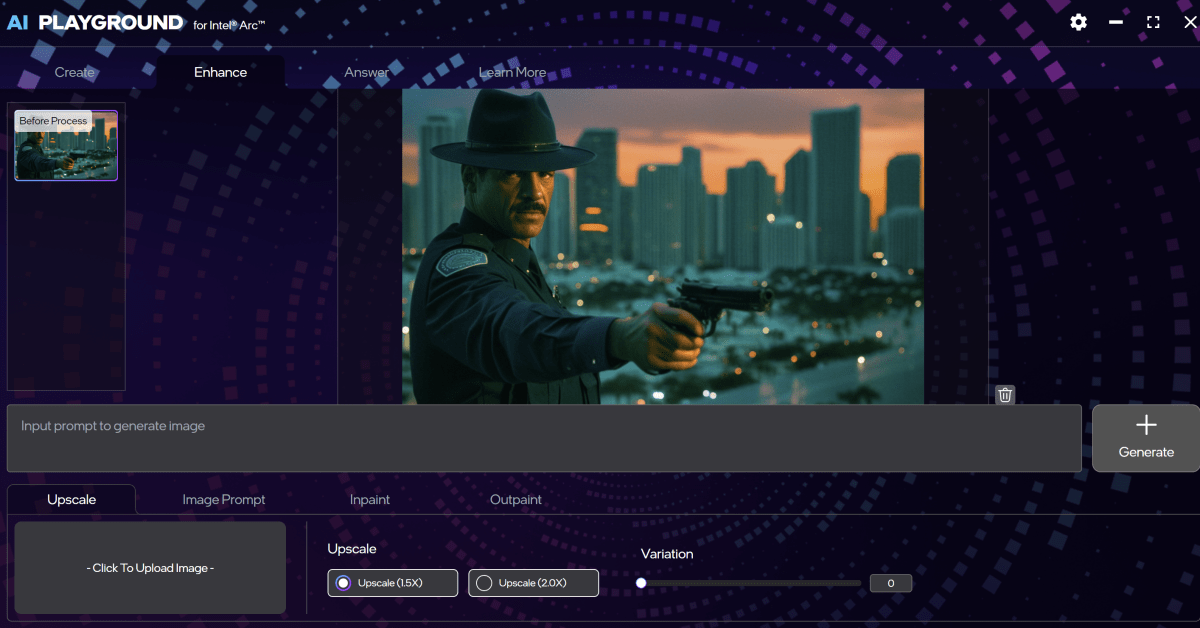
Mark Hachman / Foundry
The “Workflow” tab also hides some interesting utilities such as a “face swap” app and a way to “colorize” black-and-white photos. I was disappointed to see that a “text to video” model didn’t work, presumably because my PC was running on integrated graphics.
The “Answer” or chatbot portion of the AI Playground seems to be the weakest option. The default model, by Microsoft (Phi-3-mini-4K-instruct) refused to answer the dumb comic-book-nerd question, “Who would win in a fight, Wonder Woman or Iron Man?”
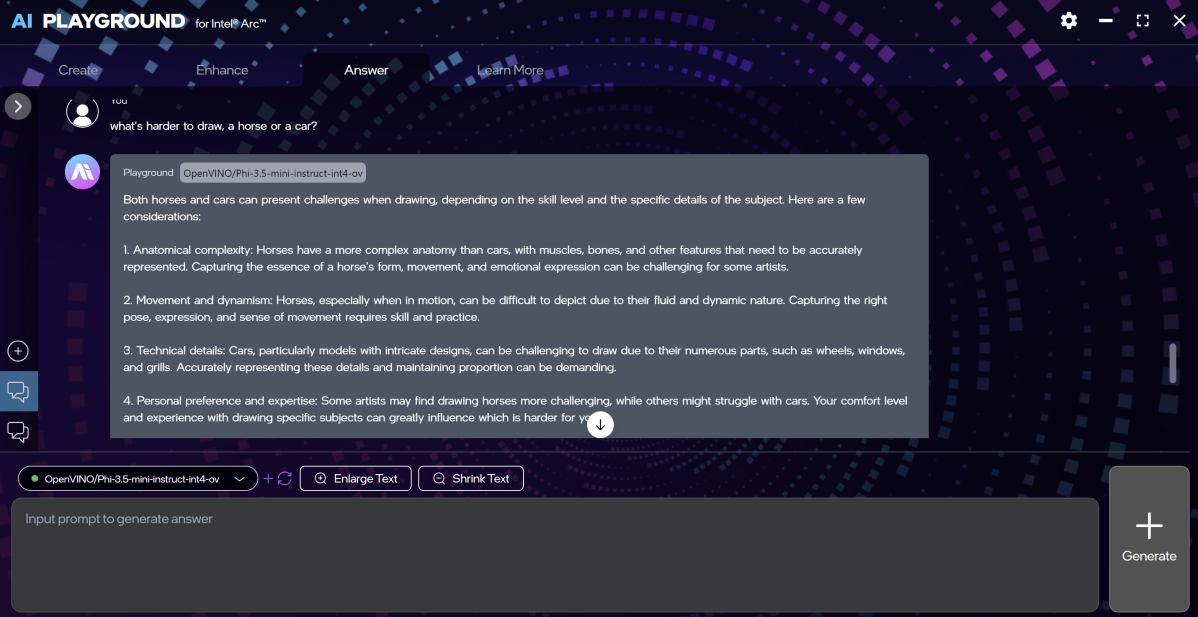
Mark Hachman / Foundry
It continued.
“What is the best car for an old man? Sorry, I can’t help with that.”
“What’s better, celery or potatoes? I’m sorry, I can’t assist with that. As an AI, I don’t have personal preferences.”
And so on. Switching to a different model which used the OpenVINO programming language, though, helped. There, the OpenVINO/Phi-3.5-mini-instruct-int4 model took 1.21 seconds to generate a response token, producing tokens to the tune of about 20 tokens per second. (A token isn’t quite the length of a word, but it’s a good rule of thumb.) I was also able to do some “vibe coding” — generating code via AI without the faintest clue what you’re doing. By default, the output is just a few hundred tokens, but that can be adjusted via a slider.
You can also just import your own model, too, by dropping a GGUF file (the file format for inference engines) into the appropriate folder.
Adapt AI Playground to AMD and Nvidia, please!
For all that, I really like AI Playground. Some people are notably (justifiably?) skeptical of AI, especially how AI can make mistakes and replace the authentic output of human artists. I’m not here to argue either side.
What Intel has done, however, is create a surprisingly good general-purpose and enthusiast application for exploring AI, that receives frequent updates and seems to be consistently improving.
The best thing about AI Playground? It’s open source, meaning that someone could probably come up with a fork that allows for more GPUs and CPUs to be implemented. From what I can see, it just hasn’t happened yet. If it did, it could be the single unified local AI app I’ve been waiting for.
via PCWorld https://www.pcworld.com
March 20, 2025 at 08:06AM